%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# 3D Scene

SCENIC Model
SCENIC is a text-conditioned scene interaction model that adapts to complex environments with varying terrains, supporting user-specified semantic control through natural language. The model navigates 3D scenes using user-defined trajectories as sub-goals and textual prompts. SCENIC employs hierarchical reasoning methods in scene understanding, achieving seamless transitions between different motion styles through frame alignment of movement and text. This technology is significant as it generates character navigation movements that comply with real-world physics and user instructions, playing a crucial role in virtual reality, augmented reality, and game development.
Game Production
45.0K
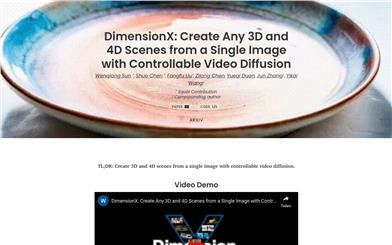
Dimensionx
DimensionX is a 3D and 4D scene generation technology based on a video diffusion model, capable of creating controlled perspectives and dynamic variations from a single image. The main advantages of this technology include high flexibility and realism, enabling the generation of scenes in various styles and themes based on user-provided prompts. Background information indicates that it was developed by a group of researchers aiming to advance image generation technology. Currently, the technology is available for free to the research and development community.
3D Modeling
67.9K

Vividdream
VividDream is an innovative technology capable of generating explorable 4D scenes with environmental dynamism from a single input image or text prompt. It first expands the input image into a static 3D point cloud and then utilizes a video diffusion model to generate an animation video collection. By optimizing the 4D scene representation, it achieves consistent motion and immersive scene exploration. This technology paves the way for creating captivating 4D experiences based on diverse real images and text prompts.
AI image generation
60.2K
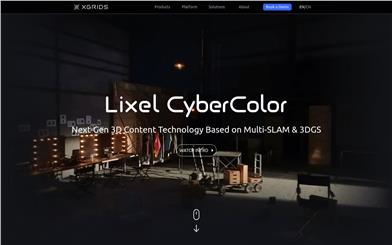
Lixel CyberColor
Lixel CyberColor (LCC), an advanced technology product developed by XGRIDS, revolutionizes the creation of 3D scenes. LCC can automatically generate infinite 3D scenes with cinematic-quality effects using Multi-SLAM and Gaussian Splash technology. Its core advantage lies in its precise capture and reproduction of real-world details, bringing realistic experiences to fields like virtual reality, game development, and film production.
XGRIDS, as an integrated hardware-software solution, showcases its powerful capabilities in high-precision 3D reconstruction and intelligent space computing at scales ranging from micrometers to kilometers. Utilizing the Multi-SLAM algorithm and optimized 3DGS technology, it automatically creates hyper-realistic large-scale 3D models for an immersive experience. Optimized algorithms achieve realistic rendering effects, while data compression technology reduces model size by 90%. Integrated LiDAR technology achieves centimeter-level model precision, and AI-driven dynamic object removal algorithms are provided. LCC plugins and SDKs are released for use in Unity, UE, Web, and mobile platforms, providing powerful support for 3D content."
AI design tools
81.1K
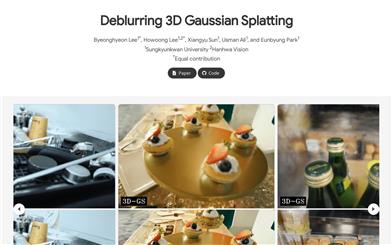
Deblurring 3D Gaussian Splatting
3Deblurring 3D Gaussian Splatting is a novel neural field deblurring framework based on a recently proposed rasterization method, incorporating 3D Gaussian and rasterization. Utilizing small multi-layer perceptrons (MLPs), this product can reconstruct detailed, clear images from blurry images simultaneously with real-time rendering. The product increases point cloud density during training by employing a K-Nearest Neighbors (KNN) algorithm to add extra points and applies loose pruning to 3D Gaussian based on relative depth, preserving more 3D Gaussian information. Multiple experiments have validated the effectiveness of this product in deblurring.
AI image enhancement
72.3K
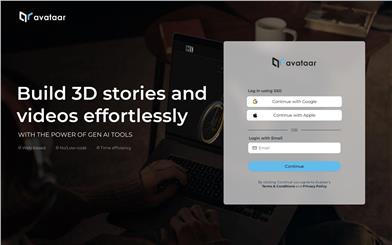
Avataar
Avataar is a platform that leverages generative AI technology to provide users with immersive visual content creation capabilities. It enables users to quickly create 3D space scenes, virtual characters, and interactive videos without any coding. Avataar empowers creators to tell stories more efficiently and deliver better visual experiences to consumers. The platform offers a web-based, no-code solution, allowing users to log in quickly using their Google, Apple, or email accounts. Avataar boasts powerful AI generation capabilities, aiding users in visual creation and significantly boosting work efficiency.
AI design tools
53.5K
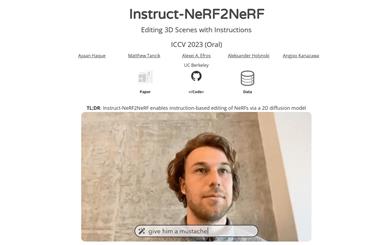
Instruct NeRF2NeRF
Instruct-NeRF2NeRF is an instruction-based editor for editing NeRF scenes. It uses an image-conditional diffusion model (InstructPix2Pix) to gradually edit the input image while optimizing the underlying scene, resulting in an optimized 3D scene that conforms to the editing instructions. We demonstrate that our method can edit large-scale real-world scenes and achieve more realistic and targeted edits than previous work.
AI image generation
56.6K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
46.1K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.6K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
45.3K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
44.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.9K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
42.0K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M